
So, this week concludes our migration to S3 for this component of our system, and it’s been a rather epic journey. As a sigh of relief, I made a post on reddit, and was overwhelmed with the response. Over 100 upvotes and 65+ comments, was rather unexpected.
From the comments, I thought maybe this was a good excuse to return to writing on this blog, and document the migration and issues we dealt with and how we overcame them for all to (maybe) read.
The problem
Where did we start? The system we work with is approximately 15 years from inception now. We’ve grown a LOT in that time. I’ve been with the business for 13 of those years, so seen and been involved in a lot of it. Sadly, with all things old, comes technical debt.
About 2 years ago, we made the decision to migrate to AWS. This in itself was a massive undertaking, due to a lot of segregated components, old legacy and non-legacy systems with under-documented interactions, and at the same time, rather rapid growth, both in terms of staff, but also clients and the system(s) themselves.
We set a goal to have our primary systems migrated within 12 months. We missed that by another 6 months, but at the 18 month timeline, we managed to cut-over. That’s probably a story for another day, but it was a rather long journey, as we had intended to not just “Lift and Shift”, but to re-engineer where we could. We wanted to at least leverage auto-scaling groups, multi-AZ presence, lamba’s in some areas, some of AWS Security measures like the ALB and WAF, CloudFront where we can, and more. For the most part, we managed to achieve this, which considering we still have a lot of the legacy components in operating, this was no small feat.
The big fish here though: All our system runs off a central Microsoft SQL database. Nothing special there, and that moved to RDS without a problem. Where we (expected, and) had problems, is with what we called our Paperwork Database. This was a second Microsoft SQL Server, hosted on premises, that was approximately 6.5TB of binary objects stored in FileStream format within the database. For those that don’t know it, this allows the SQL Server to store the binary blob as a GUID in the file system, rather than as LOB within the database MDF itself. Can lead to less chance of corruption from single multi-TB sized files, and also offers some other advantages with direct file access that we didn’t use.
Now, not only could this database not directly migrate to RDS (FileStream is not supported on RDS), cost-wise, it was going to be one helluva stupid move. We evaluated the idea of using an EC2 instance, but decided against it for 2 reasons:
- Cost. EC2 doesn’t cost as much as RDS for storage, but it’s still significantly higher than S3 costs.
- “as-a-service” - Part of the drive into AWS was the managed-services and their offerings. Essentially, pay more for the service, but reduce the need to manage it. Since we were heavy on developers, and light on the Sys-Admin side of things, this made a lot of sense for us, and still does.
Timeline
So, we had a 12 month goal for everything except the paperwork database. We had highlighted early on that this was going to be a much bigger effort. We overshot by 6 months, but overall I was still pretty happy with that. I set a goal of 3 further months post-migration to complete the paperwork migration, and sadly, it’s been just on 7 months, so overshot, but not by too much.
Driving Pressures:
Costs, again, are a factor here. We plan to shut-down our on premises (Co-Location) servers, so this was a big blocker to doing so, and every month this took to migrate, was another month paying for the co-location.
Backups were the other. While we had a rather decent infrastructure for backups (Veeam, 2 co-located servers for primary and archival backups, plus off-site), our primary infrastructure was questionable (don’t get me started on hyper converged systems!), and this particular backup had been starting to give me worries. Veeam/VSSS was starting to choke on the backups (Remember how I mentioned FileStream puts every binary blob into a file on the file system, when you have many millions of rows, this means many millions of files – VSSS doesn’t seem to like this at a certain point). We’d already progressed past the point of blowing out timeouts for VSSS Freezes, and disabling guest indexing. Backup jobs took > 14 hours to do now, and failures of the job was becoming more and more frequent.
We also calculated the speed of restoring from our backup servers as being quite low (network constraints, relatively low performance disks), and could have been facing 1+ weeks to restore the full backup! This would have been disastrous to the business, understandably!
The Plan
So how to attack this beast. Having ruled our EC2/RDS meant we needed to lose the database. The idea of binary data in a database, well, it doesn’t seem right to me anyway.
At a high level, this database contained 2 things:
- Metadata about the files stored (Filename, MIME, Size, when upload, by whom, and some other key data)
- The binary object itself
The plan we worked out was to move the meta-data into our RDS database, and the binary data to S3. Simple enough, right?
One of the comments that came up a bit on Reddit was about using Snowball as an option to avoid the 6+ month timeframe. Sadly, this really wasn’t where the hold-up was. This kind of technology change wasn’t going to sit well with most of our systems. Not to mention, getting the data out of the database and onto a snowball would have required custom tooling to do properly, at which point, we might as well have made our own.
We started with Amazon’s Database Migration Tool, as it can drop certain elements from the schema when replicating, but unfortunately it tended to glitch out, and dropped other objects along the way. It was close to getting our metadata over, but not quite.
In the end, we built our own tools to do the bulk-copy of the meta data, as well as the S3 storage.
The plan ended up being the following steps:
- Create an S3 bucket for each table in the database. Not a huge number, but enough to separate the types of attachments we store.
- Since FileStream enforces a
GUID column in the table, we decided to use that as our S3 key. Performance isn't a major issue, and AWS have most recently announced changes that mean flat storage in S3 isn't bad anyway. Since we could have had 10,000 files all called "paperwork.pdf", filenames weren't going to work and we wanted to keep it flat, so we use the GUID as the S3 key, with an extension. - This means we get to save a file as XXX-XXX-XXX.PDF, and the metadata row in the database tells us the real filename.
- We chose this method so we can modify filetypes and keep the originals. For example, we have actually made a lambda that if a XXX-XXX-XXX.DOCX gets uploaded, a lambda fires off, and converts the DOCX to PDF, and writes it back to the S3 Bucket as XXX-XXX.PDF. Now our “fetch” system can retrieve either the original or the PDF version of the same file.
- We identified that of all the integration points the paperwork have, there are only a handful of places that WRITE to the storage, many more that read. So this is where we decided to start.
- We made a web service API for writing files. This was in .NET (Visual Basic, as that is where the rest of our stack is at the moment), and ended up being pretty straight-forward. It can be called internally from our main application, or externally via our other applications. It takes the needed metadata, a directive for which table/bucket to store in, and the binary object. It then inserts the meta data into the database, gets back the GUID from the row, and inserts the binary into S3. At the early stages, it did this to the old paperwork server (so old legacy reads would get the binary still), and also to S3.
- This started to give me a feeling of safety, as I knew every single row that was writing from this point forward, was in BOTH systems, so even if we had a failure of the on-prem server, I still had this data. Baby steps!
- Each application was now in turn modified to use the new save systems. For some, this was easy, for others more work. We spread this load across various developers, and timeframes. Some got done earlier than others.
- At the same time, we developed the Read API/WebService. Again, .NET, and again, internally and externally accessible as required. This was built with a fall-back mechanism. It would prefer S3 as its source. So it would take in a few keys, find the GUID based on those keys, and then check S3 for it. If it existed, it would fetch from S3 as a memory stream and service back to the client. If it didn’t exits, it would check the binary FileStream column and return that.
- Migrating the older applications to use this took longer. This was the bulk of the timeframe to achieve, but it was slowly chipped away at.
- We created our own tooling to pull row by row data from the database, and upload it to S3. This was randomised to allow multiple thread to run at once. This took a few months to run, but this was mainly restrictions on run-time, to not impact production workloads. But every row that it pulled and copied, was one less file I’d lose in the event of a catastrophic failure.
- We also made another tool that copied the metadata from the old server to identical tables on the RDS instance, just minus the binary column. Each of these tools recorded their actions so we knew which data was copied and what wasn’t.
As the months progressed, we got to a point where I was more and more confident. About 2 months ago before completion we reached 100% migrated. But still rows were appearing in the old server. Rows not marked as copied to S3! How was this happening!
Investigation led us to find that the issue was 2 old services that generated invoices and attached the documents, and had been missed in the initial scoping for “write” operations.
The Cutover
Stage 1 of the cutover was to move all read operations for the metadata to the RDS instance instead of the old server. This meant all traffic for reads should stay 100% within AWS now. Then we shut off the sync tools and waited. If rows continued to appear that weren’t being copied, we’d know about it now, as they’d essentially be invisible to the system.
Amazingly, 1-2 more did show up! There was a really small side part of one of the web portals that had also been missed. This was patched out with a rapid hot-fix, and we were good. At this point, I wasn’t prepared to back-down. If hurdled came up, we HAD to clear them and proceed.
After a week of running at Stage 1, we moved to the final cutover. We took out all “fallback” code form the APIs. Both writing to the old server at all, and also the fall-back reads. Now if something didn’t exist in S3, we’d be getting an error.
After a near-heart-attack moment when an entire category of paperwork failed to load (I thought we must have somehow missed copying a whole type of paperwork!), it turned out to be a bug in the S3 fetch code. We’d been using the “fallback” for 100% of transactions here! (Lesson learnt: Some logging on the fallback catches could have caught this earlier!) - so in the end, and easy fix.
Then, we made the final action. Powering off the VM. After watching it for 3 further days, seeing no new rows added, no logins occurring, it was time. Now, shutting down a hated VM doesn’t allow you to “go all office space” on it, it’s still a satisfying click.
As week post-shutdown, so far, I’m happy to say I haven’t yet had to power it on for a single cross-reference! It will be a long while yet before I delete that VM from the host, and we’ll likely never delete the backups that we do have (I’m actually making a fresh FULL backup from the powered off VM now for archival), but I’m personally really pleased with the outcome.
There were some day-one glitches when the shutdown finally happened, mainly around some quirky odd places that we HAD already patched to use the API to get the binary, but some edge parts where it ONLY read the meta-data, and was still pointing to the old server.
Results
So we’re now storing all our files in S3. From here we’ve got versioning enabled, so we’ve got delete and overwrite protection at the bucket level.
Sadly being in Australia, we only have one region available, so we can’t use Cross Region Replication for the bucket, without violating our own policies regarding storage within the country. If AWS ever adds another Australian Region, we’ll be all over it.
We’ve recently enabled Intelligent Tiering. We rarely ever delete documents. 15+ years of business and growing at a scale of clients and data we’d never have imagined on day one, and rarely a deletion. Most of this data stays cold. It’s knowing it’s there at a mouse click that matters, so S3’s tiering system is brilliant. AWS takes care of what’s hot data and what’s cold, and how to manage that, and saves us money while doing so!
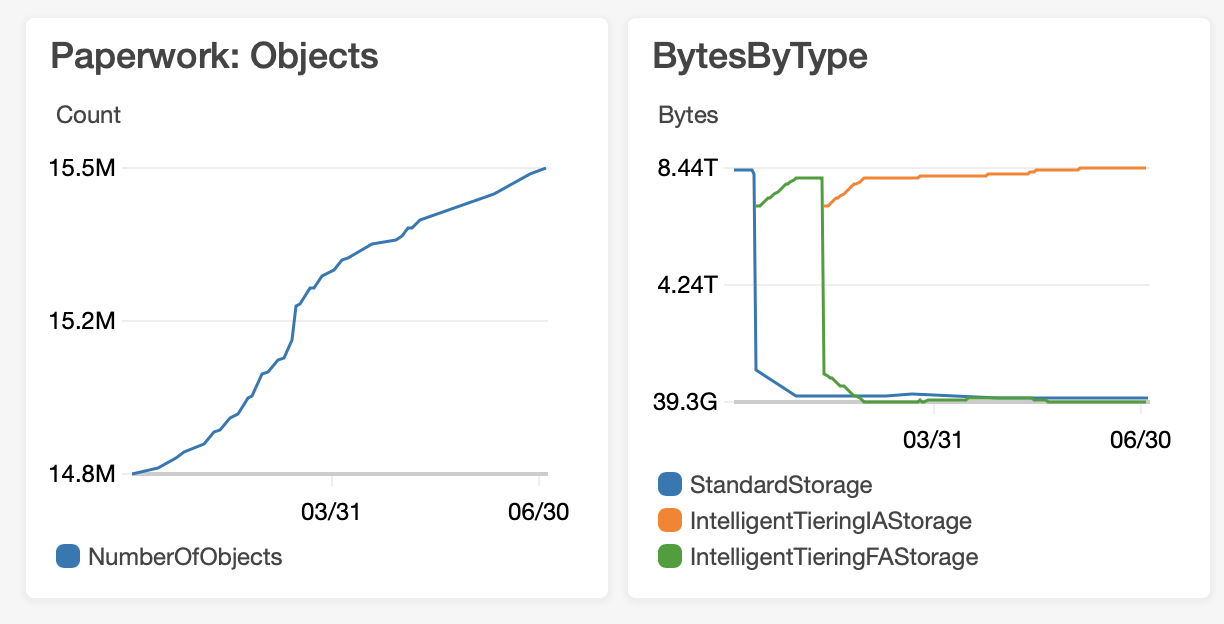
This shows 6 months of file count, and storage type. You can see where we enabled Intelligent Tiering.
We’re now over 8.4Tb in this bucket alone, and there are others too, so a lot has grown since the 6.5Tb started the migration journey.
Conclusions
Well, at the end of the day, I feel like I can sleep better now. Not only do I have my whole production system on a Multi-AZ platform on a really reliable backing, I’ve now got my biggest worry migrated away from on-premesis, away from unreliable backups and underpinning infrastructure, and gained, speed, reliability, durability and cost savings in the mix for the troubles.
Could we have done this faster? Of course we could, but to allow for BAU, and as minimal of interruption as possible, the timelines were somewhat needed.
One suggestion that came from the Reddit post was to use Glacier for deletes, and that’s something we’ll be looking into now as well. We’ve still got a few maintenance things to look at, and some improvements around the API’s themselves, but overall, I’m pretty pleased with what we set out to do, and how we went about it, and what we ended up achieving.
I don’t know if many of you will read all of this, and I’ve tried to stay away from too much technical details, and remain at a higher level, but if you have any questions, please do reach out to me, I’m always happy to help others in similar boats.